MYSQL 报错注入
Updatexml
updatexml(XML_document,XPath_string,new_value):该函数的作用是修改xml文件中数据,
XML_document表示xml文件名,这个随便你取什么;XPath_string指的是你修改的字符串;new value指的是你要修改成什么值- updatexml使用时,当xpath_string格式出现错误,mysql则会爆出xpath语法错误(xpath syntax)
- 例如: select * from test where id = 1 and (updatexml(1,0x7e,3)); 由于0x7e是~,不属于xpath语法格式,因此报出xpath语法错误。(ps:0x7e就是波浪号)、
- 该函数的返回值,如果查找到了字符串,返回值为1;如果没查找到或者报错则为0
本地测试:
select * from tb1 where idd = 1 and (updatexml(1,concat(0x7e,database()),3));:

这边咱们的数据库就被暴出来了,因此这是存在漏洞的,由于我们的~不符合xml的语法,所以会报错
例题(CTFSHOW-web244):
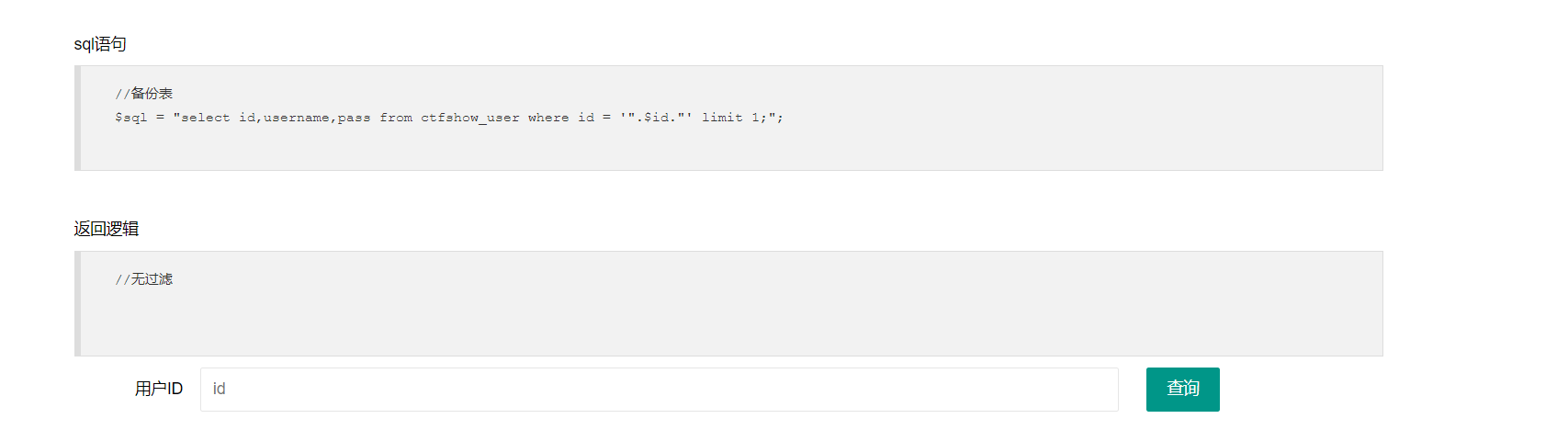
查询语句如上 $sql = "select id,username,pass from ctfshow_user where id = '".$id."' limit 1;";
这边肯定是存在一个error注入的,咱们payload:
?id=1' and updatexml(1,concat(0x7e,database(),0x7e),1)-- -:

咱们的库名就被爆出来了,接下来只需要一步步的去报表,字段即可
1 | ?id=1'and updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()),0x7e),1)-- - |

接下来就不赘述~
Extractvalue
extractvalue(XML_document,xpath_string):该函数的作用是查找xml文件中指定字符串,若查找到则返回1,否则0,和updatexml真的几乎一模一样了- extractvalue使用时当xpath_string格式出现错误,mysql则会爆出xpath语法错误(xpath syntax),这一点和updatexml一样
本地测试:
select 1,extractvalue(1,concat(0x7e,database()));
和上面同样的效果,能爆出库名
例题(CTFSHOW-WEB245):

这一题过滤了updatexml,那我们就使用extractvalue,payload ?id=1' or extractvalue(1,concat(0x7e,database()))-- -:

这边已经成功爆库,接下来步骤就同上
Group by
注意事项
这个就稍微的有点难度了,我也不废话直接上大神的链接:https://www.cnblogs.com/02SWD/p/CTF-sql-group_by.html
接下来的内容只不过是复述,给自己看看的
以及假如想在本地复现,mysql的版本很刁钻的,mysql5.6可以,其他没发现可以的版本QWQ,还有就是用MariaDB也可以复现哦
语法基础
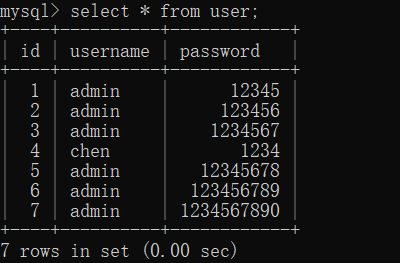
这是本文用到的表:
group by:用于结合合计函数,根据一个或多个列对结果集进行分组。
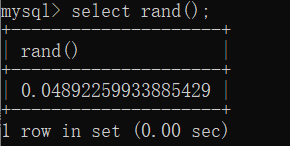
rand():用于产生一个0-1之间的随机数
warnning:当以某个整数值作为参数来调用的时候,rand() 会将该值作为随机数发生器的种子。对于每一个给定的种子,rand() 函数都会产生一列【可以复现】的数字,也就是有一些数字会是固定的!
floor():向下取整
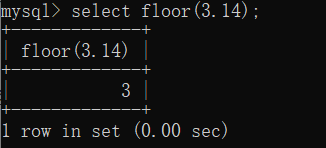
floor(rand()*2):rand()*2 函数生成 0-2之间的数,使用floor()函数向下取整,得到的值就是不固定的 “0” 或 “1”
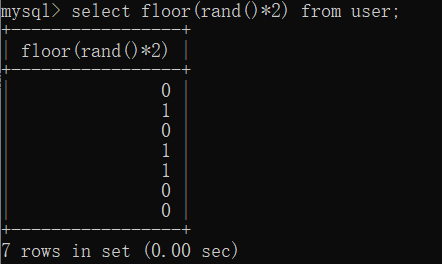
floor(rand(0)*2):rand(0)*2 函数生成 0-2之间的数,使用floor()函数向下取整,但是得到的值【前6位(包括第六位)是固定的】。(为:011011),这是因为给定了种子
Group by分组原理
首先思考一下下面3个sql语句可以得到什么:
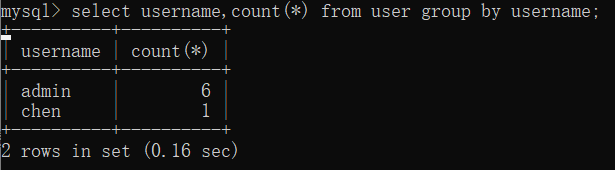
1 | 1、select username,count(*) from user group by username; |
运行结果:
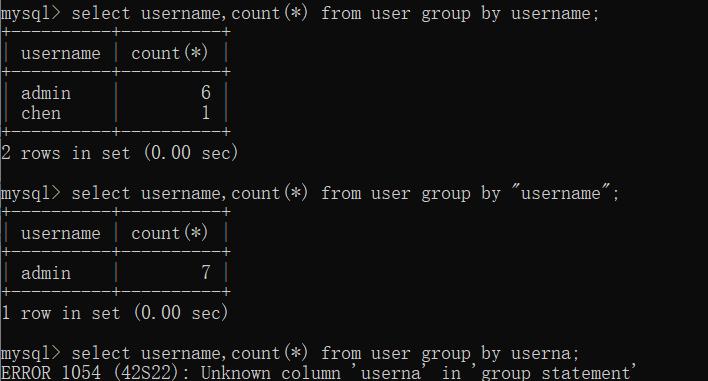
结论:
我们发现group by后面的参数可以是一个column_name(字段名),可以是一个字符串(或返回值为字符串的函数),不可以是不完整的column_name。这时你们可能会想,参数是column_name我倒是可以理解是怎么分组的,但是参数是 字符串 是怎么回事?username字段的值中没有”username”啊?只有”admin”,”chen”两个,结果怎么会是 7 呢?让我们接着往下看。
原因:
1.如果参数是 column_name,即 username,不是字符串(”username”)
语句执行的时候会建立一个虚拟表(里面有两个字段,分别是 key 主键,count(*)),如果参数是 column_name,系统便会在 user 表中【 依次查询 [相应的] 字段的值(即:参数指明的字段中的值) 】,取username字段第一个值为 admin,这时会在虚拟表的 主键key 中查找 admin 这个字符串,如果存在,就使 count(*) 的值加 1 ;如果不存在就将 admin 这个字符串插入到 主键key 字段中,并且使 count(*) 变为 1;接着取username字段第二个值也为 admin ,查找虚拟表中的 主键key 中已经存在 admin 字符串,就直接将 count(*) 加 1;…… …… ……;到username字段第四个值为 chen 时,查找虚拟表中的 主键key 字段不存在 chen 这个值,此时就将 chen 这个字符串再次插入到 主键key 字段中,并且使 count(*) 变为 1,就这样一直执行下去,直到所有的字段值分组完毕。之后系统就按照虚拟表中的结果将其显示出来。
取完username字段第四个值(即:chen)时的 虚拟表 ,如下图:
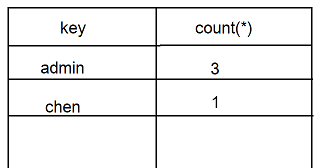
2.如果参数是字符串:”username”,而不是字段名
语句执行的时候仍会建立一个虚拟表(里面有两个字段,分别是 key 主键,count()),如果参数是字符串 “username”,那系统就不会去取user表中的字段值了,而是直接取字符串:”username”作为值,然后查找比对虚拟表中 key 字段的值,发现没有字符串 “username”,便插入 “username” 这个字符串,并将count() 变为1;然后执行第二次,在虚拟表 key 字段中查找 “username” 这个字符串,发现有,便使 count() 加 1,就这样执行 7 次,count()便变成了 7。
正题
1 | 1、select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2)); |
可以看到,user表所在的 test 数据库被成功的爆了出来。但是你们仔细观察的话会发现第二个sql语句爆率并不是100%,有时会爆不出来,为什么呢?别着急,继续往下看:
原因:在我们已经有上面的铺垫之后其实要理解这个sql group by报错注入的原理已经不难了
以第一条语句为例:select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));
首先我们知道
floor(rand(0)*2) 产生的随机数的前六位 一定是 “011011”(上面已经提到过了),
concat()函数用于将前后两个字符串相连
database ()函数由于返回当前使用数据库的名称。
concat(database(),floor(rand(0)*2))生成由database()+0和database()+1组成的随机数列,则前六个数列一定依次是:
database()+0
database()+1
database()+1
database()+0
database()+1
database()+1
报错的过程:
查询前默认会建立空的虚拟表
取第一条记录时,执行concat(database(),floor(rand(0)*2))(第一次执行),计算结果为
database()+0,查询虚拟表,发现database()+0主键值不在,然后会执行插入命令,此时又运行一次concat(database(),floor(rand(0)*2))(第二次执行),计算结果为databse()+1,然后插入该值。(即:虽然查询比对的是database()+0,但是真正插入的是执行第二次的结果database()+1,这个过程,concat(database(),floor(rand(0)*2))执行了2次,查询比对时执行了一次,插入时执行了一次)。取第二条记录,执行concat(database(),floor(rand(0)*2))(第三次执行),计算结果为
database()+1,查询虚拟表发现‘databse()+1’虚拟表存在,所以不再执行插入命令,也就不会执行第二次的concat(database(),floor(rand(0)*2)),count(*)直接加一
(即,查询为database()+1,直接加1,这个过程concat(database(),floor(rand(0)*2))只执行了一次)。
取第三条记录,执行concat(database(),floor(rand(0)*2))(第四次执行),计算结果为database()+0,查询虚拟表,发现database()+0主键值不存在,则会执行插入命令,此时又会再次执行一次concat(database(),floor(rand(0)*2))(第五次执行),计算结果为database()+1将其作为主键值,但是database()+1这个主键值已经存在于虚拟表中了,由于主键值必需唯一,所以会发生报错。而报错的结果就是 database()+1即 ‘test1’,从而得出数据库的名称 test。
由以上过程发现,总共取了三条记录(所以表中的记录数至少为三条),floor(rand(0)*2)执行了五次。
总结
现在,解释了group by报错注入的原理,想必大家已经知道为什么:
- select count(*) from information_schema.tables group by concat(database(),floor(rand(0)*2));一定可以注入成功(要成功注入,前提表中的记录数至少为三条)
- 而select count(*) from information_schema.tables group by concat(database(),floor(rand()*2));却不一定了吧。(要成功注入,前提表中的记录数至少为两条)
没错是因为floor(rand()*2)的前几位随机数顺序是不固定的,所以并不能保证一定会注入成功,但是其只需两条记录数就行了(因为它可能会产出 “0101” ,这样只需两条记录就可以成功注入,你可以试试推导一下),这也算是它的优势吧。
About this Post
This post is written by Boogipop, licensed under CC BY-NC 4.0.